Benchmark Redakcija
Benchmark Redakcija
Istraživački tim kompanije Microsoft objavio je novi model veštačke inteligencije koji pretvara tekst u govor i može proizvesti bilo čiji glas. Novom modelu, pod nazivom VALL-E, sve što je potrebno je snimak zvuka dužine tri sekunde. Nakon što završi proces učenja i nauči nečiju boju glasa, veštačka inteligencija može pustiti zvuk te osobe kako govori bilo šta, pritom zadržavajući emotivni ton, prenosi Ars Technica.
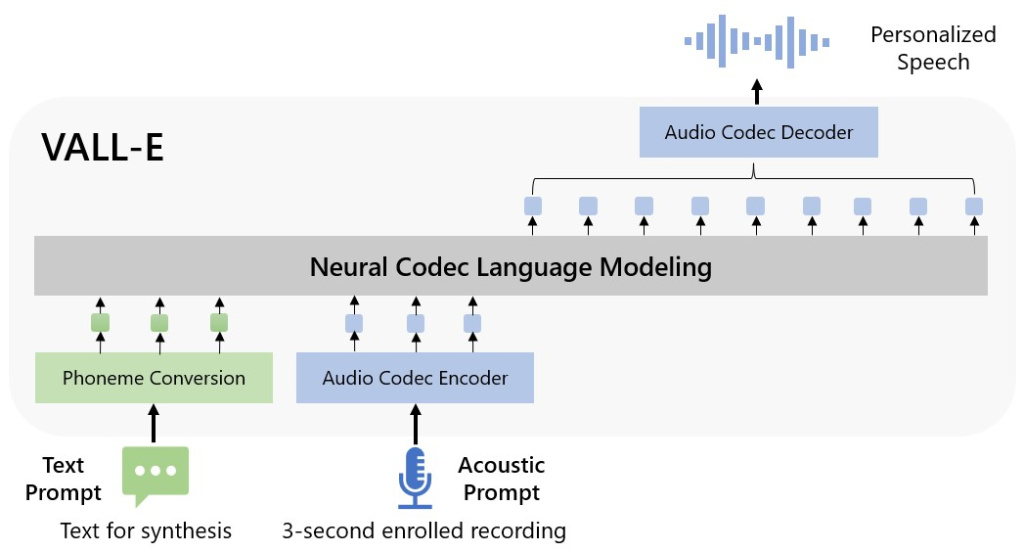
Kompanija Microsoft naziva VALL-E “model jezika neuronskog kodeka”, i izgrađen je na tehnologiji nazvanoj EnCodec koju je kompanija Meta najavila u oktobru 2022. godine. U odnosu na druge “text-to-speech” metode koje proizvode govor manipulišući talasnim dužinama, VALL-E stvara odvojene kodove audio kodeka zahvaljujući tekstualnim i akustičnim pomagalima. U osnovi VALL-E analizira kako osoba zvuči, deli tu informaciju na više komponenata (tokena) zahvaljujući EnCodec tehnologiji, i na kraju spaja deo dobijenih informacija koji se poklapa sa primerom iz prethodno učitanog snimka da bi pretpostavio kako bi osoba zvučala prilikom izgovaranja fraza koje nisu u snimku.
Microsoft je objasnio na sledeći način: “Kako bi stvorio personalizovani govor, VALL-E kreira odgovarajuće akustične tokene uslovljene akustičnim tokenima unapred učitanog zvučnog snimka. Na kraju, stvoreni akustični tokeni se koriste kako bi se kreirao konačni zvučni talas sa odgovarajućim dekoderom neuronskog kodeka.”
VALL-E se usavršavao zahvaljujući zvučnoj biblioteci kompanije Meta
Microsoft je usavršavao mogućnost VALL-E veštačke inteligencije da stvara govor zahvaljujući zvučnoj biblioteci LibriLight, koju je sastavila kompanija Meta. Sama biblioteka sadrži 60.000 časova pričanja engleskog jezika od strane više od 7.000 ljudi, najviše preuzetih od LibriVox javnih zvučnih knjiga.
Microsoft ponudio primere, od kojih određeni zvuče veoma uverljivo
Kompanija Microsoft je na internet stranici sa ponuđenim primerima prikazala rezultate VALL-E veštačke inteligencije. Zvučni snimci obeleženi sa “Speaker Prompt” oznakom su snimci dužine tri sekunde, koje VALL-E mora imitirati. Zvučni snimak sa oznakom “Ground Truth” je već snimljeni zvučni prikaz cele fraze, snimljen unapred radi poređenja sa VALL-E verzijom istog teksta. “Baseline” je rezultat koji nudi standardni pretvarač teksta u govor, dok je “VALL-E” verzija ona koju sama VALL-E veštačka inteligencija kreira. Rezultati eksperimenta su mešoviti – kod nekih se čuje da su u pitanju kompjuterski generisani, dok drugi mogu veoma jednostavno biti zamenjeni pravim glasom.
Radi očuvanja vokalnog i emotivnog tona, VALL-E takođe može imitirati i različita akustična okruženja, pa tako na primer da bi rezultat zvučao kao telefonski razgovor biće dodati akustični efekti, kao i frekvencije telefonskog razgovora.
Microsoft svestan rizika koju tehnologija nosi sa sobom
Svesna potencijalnog rizika koju tehnologija donosi, kompanija je izjavila: “Budući da VALL-E može rekreirati govor koji zadržava i identitet, tehnologija sa sobom nosi i potencijalni rizik od korišćenja u pogrešne svrhe. Da bi izbegli ovakve rizike moguće je napraviti detektor koji će utvrditi da li je zvučni snimak kreirao VALL-E.”